
A quoi cela peut-il bien servir ? Dans un premier temps, à assouvir votre curiosité! Si par exemple vous souhaitez savoir à quoi ressemblait votre site préféré il y a 5 ans ! Mais cela permet aussi de récupérer tout ou partie d’un ancien site Internet.
En effet, si vous perdez votre site Internet et que vous n’aviez pas de solution de sauvegarde (backup) en place, il peut être intéressant de pouvoir remonter dans le temps pour retrouver une image de votre site à une date antérieure, notamment pour récupérer une information précise.
Il existe quelques solutions qui permettent cela, mais nous allons vous présenter dans cet article celle qui est la plus complète en terme d’enregistrement des données.
Archive.org, l’INA d’Internet !
Archive.org est une une bibliothèque numérique gratuite sur internet. Le site est développé et géré par l’Internet Archive, une organisation à but non lucrative basée aux États-Unis et fondée en 1996 dont la mission est « simplement » d’archiver le web.
Comment ça marche ?
Outre les millions de fichiers numériques (livres, musiques, etc.) mis à disposition par le site, Archive.org fait des captures des sites présents sur la toile. Ces captures, appelées des snapshots, sont consultables directement sur le site Internet de l’organisation. La fréquence des archives varie selon l’importance du site (i.e. son classement par rapport aux autres sites).
On y compte aujourd’hui 452 milliards de pages enregistrées; ce qui en fait une base de données gigantesque !
Attention : Archive.org n’est pas une solution de sauvegarde mais d’archivage. Elle ne remplace donc pas les backups réguliers que vous devez faire de votre site. En effet archive.org ne garde qu’une copie statique du site (HTML/CSS) mais n’enregistre pas la partie dynamique (PHP, etc.)
Faire une recherche sur Archive.org
Pour effectuer des recherches, Archive.org se base sur un outil développé par Brewster Kahle qui permet de lire l’index et d’afficher le résultat. Cet outil est appelé Wayback Machine (la machine à remonter dans le temps en français).
exemple :
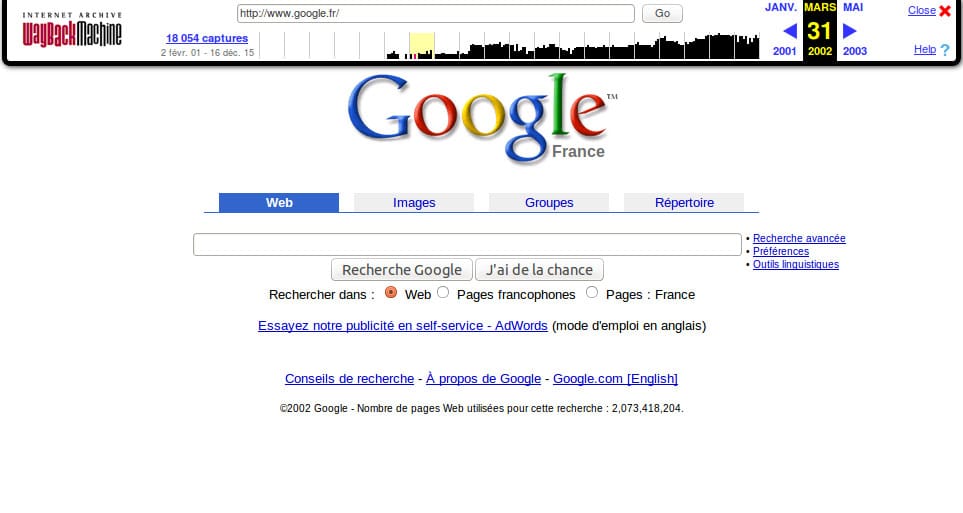
Le capture d’écran ci-dessus montre le résultat d’archive.org pour une recherche effectuée avec le mot-clé « www.google.fr ». On voit donc à quoi ressemblait la version française du moteur de recherche Google le 31 mars 2002.
Peut-on tout trouver sur archive.org ?
La réponse est clairement non. D’une part archive.org ne fait pas de snapshots à chaque instant. Il se peut qu’une information que vous recherchez n’ait pas été capturée à cause de l’espacement dans le temps entre les captures.
Il est important de noter qu’archive.org se base sur l’Alexa rank pour trouver les sites à indexer. Plus le site recherché est (ou fût) haut dans le classement Alexa, plus vous avez de chances d’y trouver de nombreux snapshots.
N’hésitez pas à faire des recherches sur archive.org et à nous faire par de votre avis sur cet outil dans les commentaires!





Join the conversation